Easily Customizable OCR for the Social Sciences
EffOCR (EfficientOCR) is designed for researchers and archives seeking a sample-efficient, customizable, scalable OCR solution for diverse documents.
Vast document collections remain trapped in hard copy or lack accurately digitized texts. Using optical character recognition (OCR) to digitize public domain collections on a large scale entails several challenges:
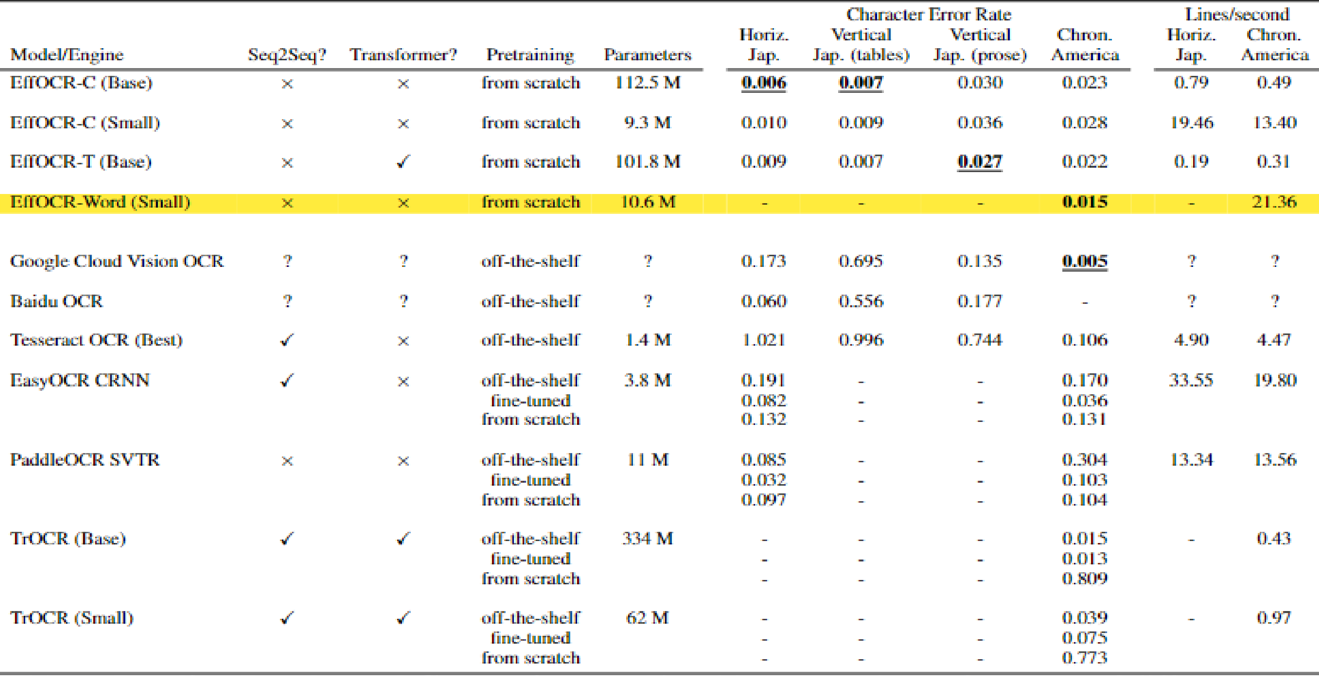
- Accuracy. Digitized texts need to be sufficiently accurate for end users’ objectives, which are highly diverse. Accuracy can be particularly central for quantitative applications, for which small errors can create major statistical outliers. Models for lower resource languages, if they exist, tend to perform much worse than models for high resource settings like English.
- Cost. The OCR solution must be cheap to deploy, given document collections whose size numbers in the millions or even billions of pages. Commercial engines - as well as large open-source OCR models - fall well short of this requirement.
To meet these objectives, we developed EffOCR, an open-source OCR package designed for researchers, libraries, and archives seeking a computationally and sample efficient OCR solution for digitizing diverse document collections. EffOCR has two key ingredients: 1) a novel OCR architecture and 2) a carefully designed interface to facilitate off-the-shelf OCR usage, customization via model training if necessary, and easy sharing of OCR models.